Last 26th of October I started an experimento to test how PDF documents are crawled and indexed by search engines. In particular, I was curios to understand the following things about PDF documents:
- Does Microsoft Word® headers (normally used into a professional document) make a difference?
- How much the Keyword Density in the document impact on its ranking?
- How much document properties (Title, Author, Comments and Keywords) influence the indexing?
After just one week, Google started to show some concrete results. The other search engines are still looking around; only Ask return a couple of result, but anything that I can talk about.
Scope of this document is to highlight the fluctuation that the different PDF documents made (13 in total) made day-by-day.
Those are the first – most interesting – results I collected during the past weeks for the main document returned by a SERP generated using the URK “seiunamicone”.
 Followed by the hidden results, those one that can be seen expanding the hidden menu (click on plus symbol).
Followed by the hidden results, those one that can be seen expanding the hidden menu (click on plus symbol).
 I’ve been monitoring the SERP for a while, and apart from the first days where it has been continuous fluctuations, now the results seem to be stabilized.
I’ve been monitoring the SERP for a while, and apart from the first days where it has been continuous fluctuations, now the results seem to be stabilized.
Proposing a lot of images it would probably have been muddle-headed, however I can assure you that a lot of changes took place, and I presume that looking at the SERP tomorrow, something new could be highlighted.
Just to give you an example outside the above picture, on 3rd of November the third result was a document called PDF-test-without-headers-KD43.pdf – my test n. 11. To be honest have shown it there get me confused e I wasn’t able to figure out how it was possible. That’s the reason for which I included a graph collecting the different SERPs changes.
This is the full graph.
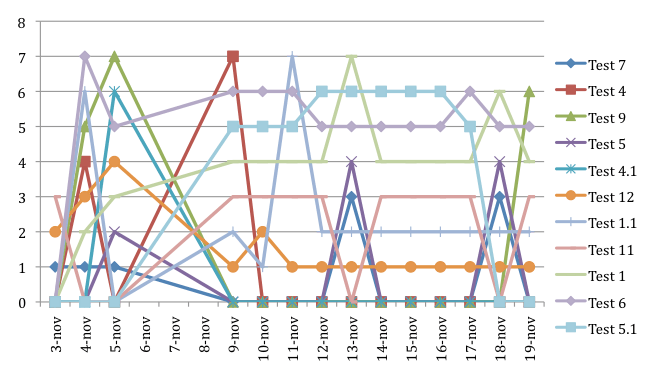
Whilst this is a graph with the documents that just take part on the SERP during the period in which I monitored it.
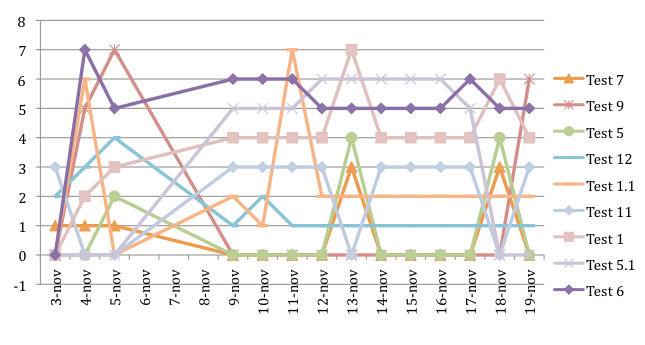
Let’s analyze it altogether, but first let me remind you something about the documents generated. I assumed a KWD of the URK “seiunamicone” split between the page (42%) and the document properties (56%) and fake headers when H1 and H2 have been created using pure emphasis instead of Word styles.
The first PDF to be indexed has been a document called Test 7 (PDF-test-without-header2-KD100.pdf). This document contains an H1 made using Word styles, a fake H2 – just emphasized text – with a KD of 100%. Just after some days, this document has been completely refused by Google SERP. Today is in the index but sit nowhere. A snugly result for test number 5, 28% KD and one header, whilst no index at all for test 3, 10 or 13 for example.
If we would like to analyze only the first three results (first one and it’s aggregate) plus the first result shown when expanding hidden results we got the following picture.
Positive results has been collected for test number 12, always been present in the SERP and now stable on position 1 from about one week, test number 1.1, with some fluctuation, but now stable on position 2, and finally test 11, that apart some daily disappear has always been on position three.
So what makes the difference for these documents?
I almost sure Google is able to interpret the RTF code contained into PDF document (most probably doing a sort of reverse engineering). This sounds like strong assert (and maybe it is, so please take it just as my personal opinion) but it’s the only explanation I was able to find when I answered to the question “Why these?”
Analyzing the SERPs, I saw that after a KWD factor, the headers get their own importance, so, today what could be the answer about the following question?
What are the factors that influence a PDF file indexation into Google? (Conclusions)
As of today, I would probably answering by saying:
- Document properties usage. It is worth adding keywords into the document properties (Title, Subject e Keywords – Comments are ignored). We can even use the Author field, but it looks like to be used for different purposes.
- Keyword density. A sufficient number of keywords in the strategic part of the document – as per HTML pages – results in a better-optimised document, especially when headers are used. But I’ve noticed another important thing; documents over a certain size (something around 100 KB) are not crawled properly.
- Header usage. Inserting keywords into the header 1 (made with Word styles, not emphasizing the text) boost the document and helps the indexation. Using an H2 is equally fine, and no particular weight difference exists between the two of them.
- Keyword proximity. When the header styles are not used, the keyword proximity plays an important role.
I believe I have not forget anything and I hope you enjoyed reading this post.